FS of NPUcore-LA
本文最后更新于 2025年7月9日 晚上
FS of NPUcore-LA
〇、概览
先使用 rtree (我自己用gpt帮助写的用rust实现的tree简化版)看一下大概
可以看到有fs根目录下有三个文件夹,分别是:
- dev :放各种特殊设备的代码
- fat32 :放有 fat32 相关的代码
- ext4(我自己加的)
所以依葫芦画瓢,现在ext4下面创建如下结构,后面再慢慢改
1 | |

一、FS 根文件
然后我们现在先从 fs 文件夹下面看看纯文件
首先,先看看 fs/mod.rs 文件,毕竟是模块声明文件
1.1 fs/mod.rs
1.1.1 lazy_static! 段
1 | |
可以看到创建了一个变量 ROOT_FD,类型是 Arc<FileDesciptor>,内部的值初始化为false, false, self::directory::ROOT.open(...).unwrap()
1.1.2 FileDescriptor 结构体
1 | |
cloexec: 表示这个文件描述符是否应该在执行新的程序(比如通过exec系列函数)时关闭。nonblock: 表示文件描述符是否设置为非阻塞模式。file: 这是一个实现了Filetrait的对象的引用计数指针(Arc<dyn File>),这意味着它可以指向任何实现了Filetrait的具体文件类型。
1.1.3 FdTable 结构体
1 | |
inner: 一个可选的FileDescriptor类型的向量,每个元素代表一个文件描述符,使用Option来允许文件描述符被标记为未使用。recycled: 一个u8类型的向量,可能是用来追踪哪些文件描述符编号已经被回收并且可以重新分配。soft_limit和hard_limit: 这些可能是指文件描述符的数量限制,软限制是可以修改的限制,而硬限制则是最大上限。
剩下的就是这两个东西的实现了,先暂时不在这里展开
⚠️TODO!
1.2 fs/file_trait.rs
1 | |
1.3 fs/filesystem.rs
1.3.1 lazy_static! 段
一段不知所云的 lazy_static! 代码
1 | |
这段代码创建了一个全局的、线程安全的 FS_ID_COUNTER 变量,初始化为0。这个计数器被 Arc 包裹,以便在多个线程间共享,并且通过 Mutex 确保在任何时刻,只有一个线程能够访问或修改计数器的值。
static ref是lazy_static!宏的关键字(由lazy_static!提供),表示声明一个静态的、可变的引用。这个变量会在程序运行时被初始化并且保持全局唯一,直到程序退出。FS_ID_COUNTER是变量的名字,可以被其他代码访问。由于是静态变量,Rust 会确保在整个程序生命周期内只有一个
FS_ID_COUNTER实例存在,并且它在多线程环境下是安全的。
Arc<Mutex<usize>>是FS_ID_COUNTER的类型,下面是它的具体含义:- Mutex:
Mutex是一种互斥锁,用于保证数据在多线程环境中的安全访问。只有一个线程可以访问被Mutex包裹的数据,其他线程必须等待直到该线程释放锁。
- Mutex:
1.3.2 FS 枚举
枚举类型 FS,包含文件系统类型
1 | |
可以看到这里有
- NULL:应该是找不到类型的时候用的
- Fat32:已经实现好的文件系统支持
- Ext4: 我添加的还没有实现的文件系统支持
1.3.3 FileSystem 结构体
FileSystem 数据结构
1 | |
剩下的就是FileSystem的方法,只有一个new方法(关联函数)
1 | |
可以看到,FS_ID_COUNTER 先上锁然后加 1
然后将加 1 后的值给 fs_id
1.4 fs/directory_tree.rs
1.4.1 lazy_static! 段
首先是一坨 lazy_static! 代码
1 | |
可以看到包含四个变量,全部都是 pub static ref ,所以只能放在 lazy_static! 宏中
- FILE_SYSTEM:类型为
Arc<EasyFileSystem>,即用fat32模块内部的efs模块(很明显这里需要做一步解耦,将efs拆分出fat32,然后添加对ext4的支持) - ROOT:类型为
Arc<DirectoryTreeNode>, 即文件系统的根目录节点 - DIRECTORY_VEC:类型为
Mutex<(Vec<Weak<DirectoryTreeNode>>, usize)>,存储一个元组:Vec<Weak<DirectoryTreeNode>>:这是一个Weak引用的向量,Weak引用用于避免循环引用,表示对目录树节点(DirectoryTreeNode)的弱引用。这意味着这些引用不会阻止目录节点的内存被回收。usize:初始化为0,用于计数,每次delete_directory_vec()操作后这个值都会自增1。
- PATH_CACHE:
PATH_CACHE用于优化路径查找。当系统访问路径时,它可以缓存路径和目录节点,避免每次都进行完整的路径解析,提高效率。
1.4.2 directory_vec 函数组
然后是三个关于 directory_vec 的函数
1 | |
即增、删、改
- insert:往
DIRECTORY_VEC塞一个inode - delete:用于实现
Drop特征,使DIRECTORY_VEC的内部的计数器加1,当计数器值大于等于节点数量的一半时,调用update进行优化处理并重置计数器为0 - update:优化处理无效的节点:创建一个新变量(与
DIRECTORY_VEC第一个字段类型相同),遍历DIRECTORY_VEC获取没被Drop的节点,push到这个新变量里面,然后将新变量的值赋给DIRECTORY_VEC
1.4.3 DirectoryTreeNode 结构体
1 | |
children是一个RwLock,表示该字段可能会被多个线程同时读,但只有一个线程可以写。RwLock确保多线程访问时的数据一致性。
实现了 Drop 特征,该特征在被触发的时候(也即 DirectoryTreeNode 被销毁的时候)会调用上面的 delete_directory_vec 函数。
实现了如下方法:
1 | |
1.4.4 init_fs 函数组
接着是 init_fs 初始化文件系统函数
1 | |
可以看到包含了三个初始化函数:
1 | |
1.4.5 其他
oom
即 Out Of Memory
1 | |
用于处理OOM的情况,被 mm 模块调用
会调用 tlb_invalidate 函数,在 arch/la64 中实现
会调用 update_directory_vec 函数
返回被释放的内存页数(只找到如下部分会返回不为 0 的值):
src/fs/fat32/vfs.rs
1 | |
1.5 fs/poll.rs
1.5.1 bitflags! 段
1 | |
1.5.2 PollFd 结构体
1 | |
含有三个字段。
1.5.3 ppoll 函数
poll()函数用于等待一组文件描述符(poll_fd)上发生某些事件,或者等待时间限制到期。如果设置了事件,poll()会检查指定的文件描述符上的事件是否发生。与select()函数的工作方式不同,poll()使用的是 OR 的方式(即文件描述符上的多个事件可以同时发生),而select()是 AND 的方式(即多个事件条件必须同时满足)。
1 | |
1.5.4 FdSet 结构体
1 | |
FdSet 使用一个包含 16 个 u64 数组 (bits: [u64; 16]) 来存储文件描述符的位图,每个 u64 对应一个文件描述符的 64 个 bit 位。
方法实现:
1 | |
然后为 FdSet 实现了 Bytes 特征,该特征定义在
src/lang_items.rs
1 | |
1.5.5 pselect 函数
类似于 Unix 系统中的 pselect() 系统调用,目的是通过轮询多个文件描述符,等待某些事件发生,如可读、可写或异常状态。它可以设置超时,并且支持信号屏蔽(sigmask)。
1 | |
pselect是一个用于轮询多个文件描述符的函数,它可以等待某些事件的发生(如可读、可写或异常),并支持超时和信号屏蔽。- 它的工作原理是通过不断轮询文件描述符集合,检查它们是否准备好,如果有准备好的文件描述符,函数会返回相应的数量。如果超时或没有事件发生,函数会退出。
- 它使用了
FdSet来表示文件描述符集合,并通过与fd_table中的文件描述符进行比较来确定它们是否就绪。
1.6 fs/layout.rs
1.6.1 bitflags! 段
首先是三大段 bitflags! 宏,全部都是常量,用于设置对应标志位
OpenFlags——O_xxx:表示文件打开时使用的标志位
- O_RDONLY
- O_WRONLY
- O_RDWR
- O_CREAT
- O_EXCL
- O_NOCTTY
- O_TRUNC
- O_APPEND
- O_NONBLOCK
- O_DSYNC
- O_SYNC
- O_RSYNC
- O_DIRECTORY
- O_NOFOLLOW
- O_CLOEXEC
- O_ASYNC
- O_DIRECT
- O_LARGEFILE
- O_NOATIME
- O_PATH
- O_TMPFILE
SeekWhence——SEEK_xxx:
- SEEK_SET
- SEEK_CUR
- SEEK_END
StatMode——S_xxx:定义文件类型和文件权限
S_IFMT:掩码,用于从
st_mode提取文件类型S_IFSOCK:socket 套接字
S_IFLINK:symbolic link 符号链接
S_IFREG:regular file 常规文件
S_IFBLK:block device 块设备
S_IFDIR:directory 目录(文件夹)
S_IFCHR:character device 字符设备
S_IFIFO:FIFO 命名管道
设置ID标志位组
S_ISUID:设置用户ID位
S_ISGID:设置组ID位
S_ISVTX:Sticky 位,通常用于 目录,是一种特殊的权限位。当某个目录设置了 Sticky 位时,目录中的文件只能由文件的拥有者、目录的所有者或 root 用户删除或重命名。这通常用于共享目录(例如
/tmp),以防止用户删除或修改其他用户的文件。用户权限标志位组
S_IRWXU
S_IRUSR
S_IWUSR
S_IXUSR
组权限标志位组
S_IRWXG
S_IRGRP
S_IWGRP
S_IXGRP
其他用户权限标志位组
S_IRWXO
S_IROTH
S_IWOTH
S_IXOTH
1.6.2 常量
1 | |
即下面的 Dirent(Directory Entry)的 d_name 字段的限定大小值
1.6.3 Stat 结构体
然后是 Stat 结构体(派生了Clone, Copy, Debug 的 Trait)
该结构体灰常重要(实际上是因为非常好理解),保存了文件的状态(从支持的文件,不支持的文件我暂时不知道会咋样)
1 | |
接着是 Stat 的方法实现
1 | |
get_ino:获取
st_ino,即inode numberget_size:获取
st_size,即文件大小new:关联函数,创建一个新的
Stat,st_uid:初始化为0st_gid:初始化为0st_blksize:BLK_SIZE,与BLOCK_SZ 相同,后者在os/src/arch/la64/board/2k500.rs内定义,大小为2048st_blocks:(st_size 文件大小 + BLK_SIZE 块大小 - 1)/BLK_SIZE这个表达式确保至少st_blocks大小为1。st_size的大小总为n * BLK_SIZE + remainder,那么经过这个式子转化后,当remainder为0,st_blocks == n当
remainder为1,st_blocks == n + 1这保证了最小块对齐。
__xxx:全部初始化为0
1.6.4 Dirent 结构体 (为啥不命名为DirEnt?)
即 Directory Entry ,看注释意思是原生Linux 目录项结构,(好像就是用于文件夹)
理论上 d_name 字段并不是定长的,可以任意长,但是代码中将该字段设置为定长大小
1 | |
然后是 Dirent 的实现
1 | |
其中 d_name 大小初始化为 0 ,然后使用 copy_from_slice 从关联函数 new 中给的参数复制。
好了没了
1.7 fs/swap.rs
交换空间相关
1.7.1 lazy_static!
首先是一坨 lazy_static!
1 | |
可以看到定义了一个 pub static ref ,类型为 Mutex<Swap>,初始值为16
该引用用于为 SwapTracker 类型实现 Drop 特征
1.7.2 常量
都为
usize类型
- BLK_PER_PG:
PAGE_SIZE / BLOCK_SZ;每个交换空间页面对应的块数。一个页面的大小是PAGE_SIZE,而每个块的大小是BLOCK_SZ。 - SWAP_SIZE:
1024 * 1024;交换空间的总大小,这里设置为 1MB(1024 * 1024 字节)。该常量用于计算交换空间总量。
1.7.3 SwapTracker 结构体
1 | |
是一个元组类型的结构体,包含一个 usize类型变量
首先实现了 Drop 特征
1 | |
1.7.4 Swap 结构体
1 | |
Swap内部有两个字段
bitmap:位图,用来表示交换空间中的页面是否已经被分配。每一位表示一个页面,位为 1 表示该页面已被分配,位为 0 表示该页面未分配。block_ids:存储交换空间块编号的数组,表示每个交换空间页面(通常对应一个内存页)所对应的物理存储位置。
Swap 有 3 个关联函数:
new:创建一个新的Swap实例read_page:从交换空间读取数据write_page:向交换空间写入数据
有 7 个方法:
set_bit:位图中某一位置 1 ,表示该页已被使用clear_bit:位图中某一位置 0 ,标志该页被释放alloc_page:尝试为交换空间分配一个页面。如果找到了一个未分配的页面(位图中的位为 0),它会返回该页面的swap_id,否则返回None。get_block_ids:根据swap_id获取该交换页面对应的块 ID 列表。read:从交换空间读取数据,会调用read_page和get_block_idwrite:向交换空间写入数据,会调用上面多个函数,返回一个Arc包装的SwapTrackerdiscard:调用clear_bit,将位图中的某一位清零
1.8 fs/cache.rs
二、NPUcore-LA-ext4所作的修改(增量)
先展示一下目前fs下的目录树情况
1 | |
然后是VFS调用情况
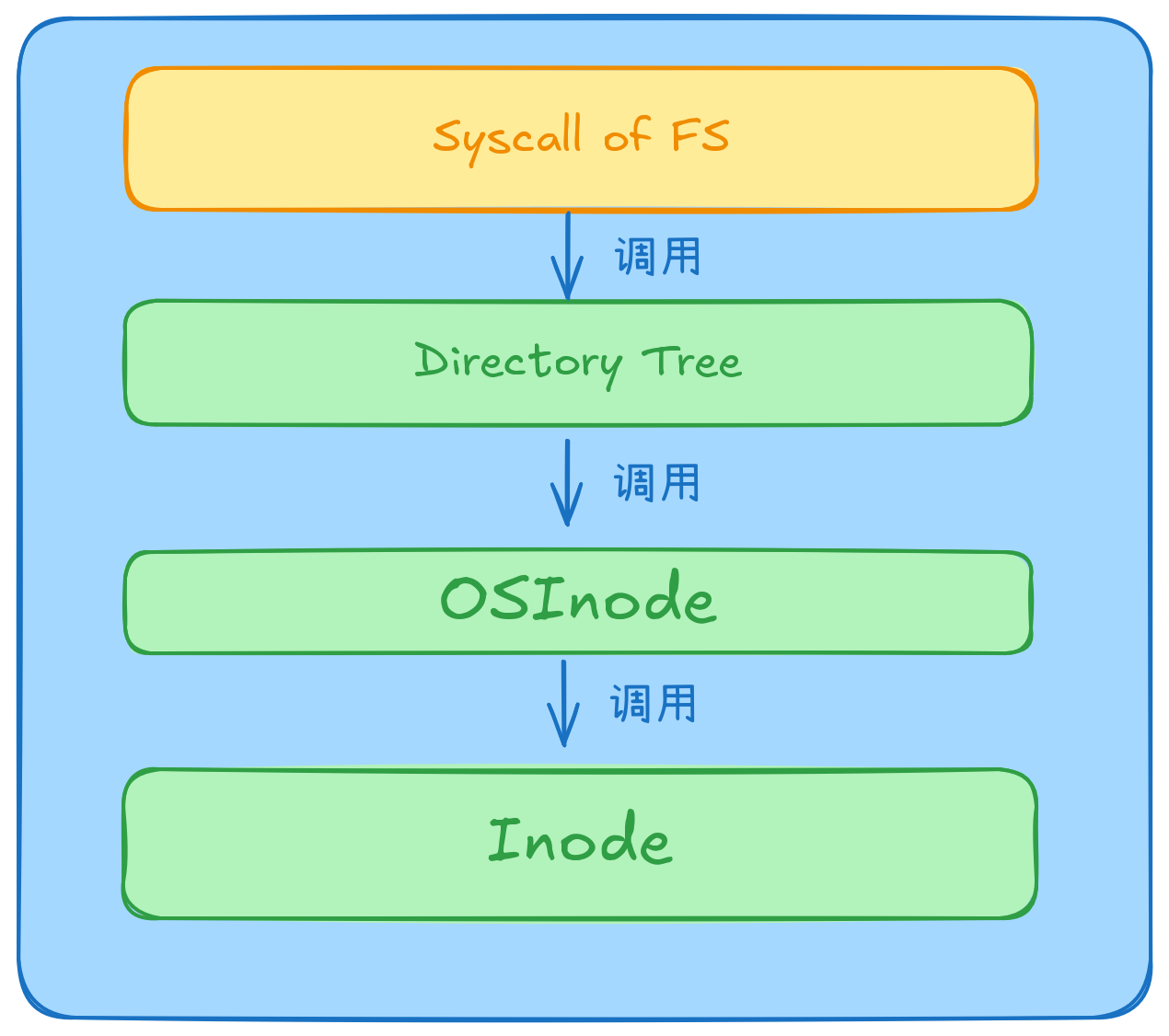
其中OSInode实现了File特征,Inode属于fat32模块,经过一番改动后,抽象成了InodeTrait,在OSInode内部有一个inner字段,该字段由Inode类型转为实现InodeTrait特征的动态分发对象。
然后在Fat32中,因为文件是由一个簇索引链表来记录的,所以fat32::Inode内部的file_content字段实际上是一个簇索引数组。
附录
是什么
为什么
怎么做
附录一、操作系统概念
1. inode 索引节点
inode 是文件系统中的数据结构,用于存储文件的元数据(权限、大小、时间戳等)和指向文件数据块的指针,但不包含文件的内容和文件名。
通过 inode,操作系统可以管理文件的存储和访问,允许文件通过硬链接共享同一个 inode。
2. OOM
即 内存不足(Out of Memory)
3. VFS 虚拟文件系统
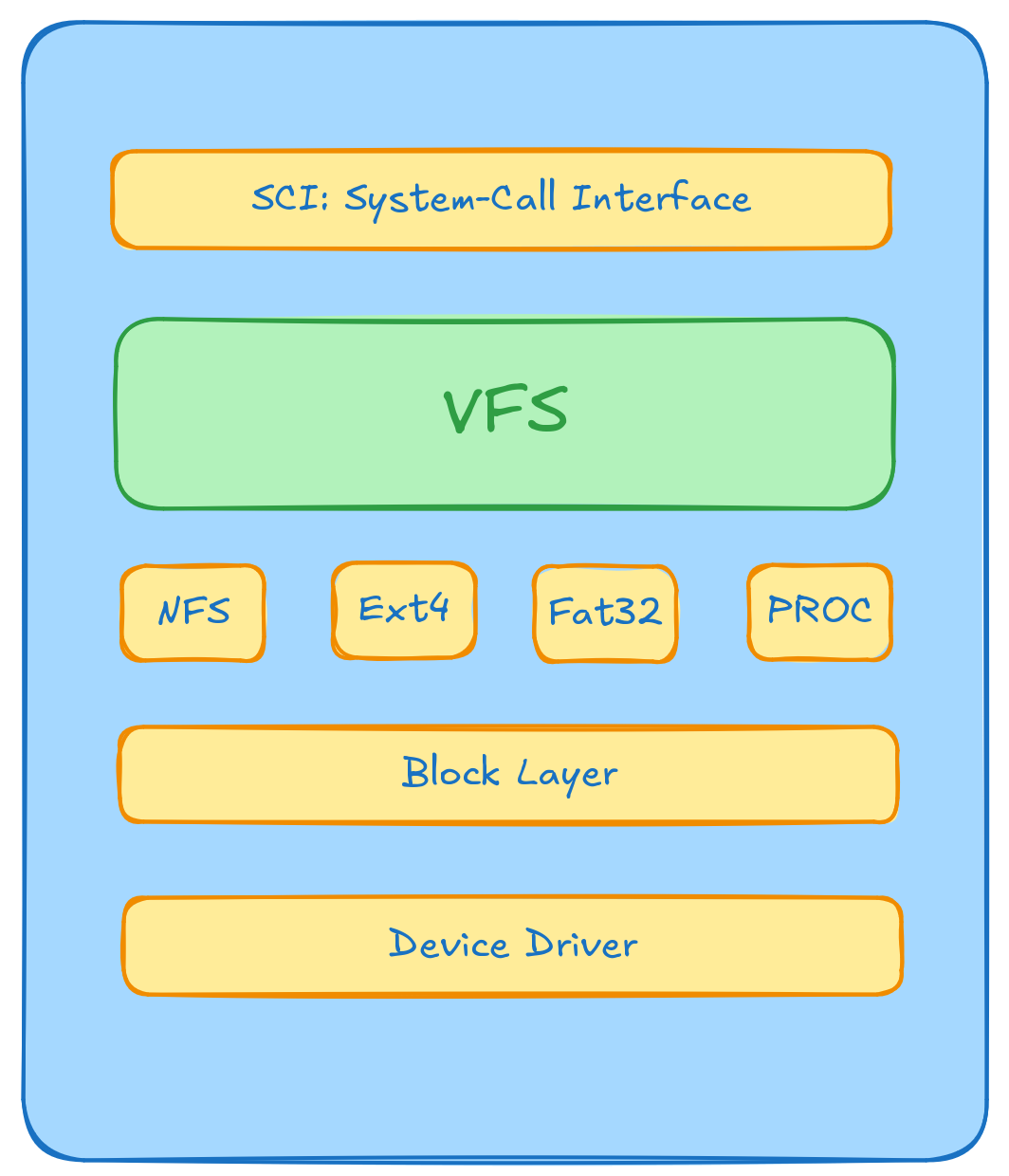
如图所示,VFS在Linux内核中大概位于那么一个位置,用户态下应用(通常是IO操作)通过用户态调用进入到内核态,再通过内核态的文件系统相关的系统调用去调用VFS的各个方法,通过VFS,内核可以对不同类型的文件系统进行操作。
如果没有VFS,用户对不同的文件系统执行同一个操作则需要复杂的、不同的操作。有了VFS之后,这些具体细节对于用户来说都是透明的——因为只需要跟VFS打交道,打开文件,告诉VFS去open一个文件就可以了,写一个文件,告诉VFS去write一个就可以了……
VFS是一种软机制,只存在于内存中。什么意思呢,每次系统初始化期间Linux都会先在内存中构造一棵VFS目录树(在NPUcore中也就是DirectryTreeNode构成的树)
通过VFS屏蔽底层的不同的调用方法,极大的方便了用户态下程序的编写。
VFS提供了一个抽象层,将POSIX API接口与不同存储设备的具体接口进行了分离,使得底层的文件系统类型、设备类型对上层应用程序透明。
4. syscall 系统调用
5. block device 块设备
附录二、Rust 语言
1. Rust 基础
ref 与 & 的区别
& 是用来创建引用的操作符,它在表达式中用于借用(不可变或可变)某个值。
ref 用于在模式匹配中解构时创建引用。它不会像 & 那样直接在表达式中借用一个值,而是在解构的过程中通过 ref 获取对值的引用。
2. Rust 特征
Drop
是什么
在 Rust 中,Drop 是一个特殊的 trait,它定义了对象销毁时需要执行的清理操作。
为什么
当一个值的生命周期结束时,Rust 会自动调用该值的 drop 方法。这个方法通常用于释放资源,进行清理操作。Rust 的内存管理是基于所有权系统的,当一个变量超出作用域或被销毁时,Rust 会自动释放其占用的资源。
怎么做
可以通过为一个类型实现 Drop trait 来自定义清理逻辑。当一个对象不再需要时(比如当它超出作用域或被手动销毁时),Rust 会调用它的 drop 方法。
1 | |
3. Rust 宏
1. lazy_static! 宏
lazy_static! 是 Rust 的一个宏,它用于声明一个静态变量,并且支持延迟初始化。普通的静态变量必须在编译时就已知其值,而 lazy_static! 允许我们在运行时初始化静态变量,只会在第一次访问时进行初始化。
形如 static ref 的用法只能在 lazy_static! 宏中使用。
2. bitflags! 宏
是什么
bitflags! 宏是 Rust 中用于简化位标志(bit flags)操作的一个宏,属于 bitflags crate 中的功能。位标志通常用于表示多个布尔状态,它通过位运算(如 AND、OR、NOT 等)将多个布尔值合并到一个整数类型的值中。这样做能够节省内存,并提高性能,特别是在需要存储多个状态时。
为什么
在 Rust 中,位标志常常用于表示一组互斥或可组合的状态,例如:
- 权限控制(读、写、执行等)
- 游戏中的多个开关(如:飞行、无敌、速度提升等)
- 系统标志(如:文件的打开模式、网络协议标志等)
如果手动实现这些位标志的管理,代码会变得比较繁琐,因为需要手动定义每个位的值,并处理位运算。bitflags! 宏简化了这个过程,它通过提供一种更直观的方式来定义和操作位标志。
怎么做
1 | |
remove 相当于对对应位置零。
4. Rust 属性
1. #[repr(xxx)] (representation)
#[repr] 是 Rust 的一个属性,指定一个类型的内存布局(representation)。通过 repr 属性,Rust 允许你控制结构体、枚举、联合体或其他类型在内存中的布局,确保它们与其他语言(例如 C 语言)或者硬件接口的兼容性。
#[repr(C)] 是最常用的 repr 属性之一。它告诉 Rust 使用 C 语言的内存布局规则来布局结构体或枚举
2. #![feature()] 实验性功能
通常写在main.rs或者lib.rs下,比方说启用向上转换功能:
1 | |
一般来说,实验性功能必须使用nightly版本的rust,同时可以使用旧版本的nightly进行编译,这些功能可能在新版本中会因为稳定而加入稳定版也就是stable中,那么在新版本中就可以不用再进行#![feature(xxx)]编写来启用。但是有时候有些功能可能在新版本中是稳定了,但是在更新的版本中又从稳定版中被踢出,那么就要继续使用这个代码块来启用功能。当然,还有更不好的情况,就是这个实验性功能在新版本直接没掉了,所以个人建议最好是先别启用实验性功能,先看看有没有平替做法。
5. Rust 高阶
1. Arc (Atomic Reference Counting)
Arc 是一个线程安全的引用计数智能指针,允许多个线程共享对同一对象的所有权。当没有任何线程持有 Arc 时,资源会被自动释放。Arc 是为了在多线程环境中共享数据而设计的。
2. Weak (Weak Reference)
弱引用,不会增加引用计数
包含的 lock().upgrade() 方法可以使其升级为一个强引用